SSIS Data flows can be really complex. Worse, you really can’t execute portions of a single data flow separately and get meaninful results.
Further, one of the key features of SSIS is the fact that the built-in data flow toolbox items can be equated to framework functionality. There’s not so much value in unit testing the framework.
Excuses come easy, but really, unit testing in SSIS is not impossible…
So meaningful unit testing of SSIS packages really comes down to testing of Executables in a control flow, and particularly executables with a high degree of programability. The two most significant control flow executable types are Script Task executables and Data Flow executables.
Ultimately, the solution to SSIS unit testing becomes package execution automation.
There are a certain number of things you have to do before you can start writing C# to test your scripts and data flows, though. I’ll go through my experience with it, so far.
In order to automate SSIS package execution for unit testing, you must have Visual Studio 2005 (or greater) with the language of your choice installed (I chose C#).
Interestingly, while you can develop and debug SSIS in the Business Intelligence Development System (BIDS, a subset of Visual Studio), you cannot execute SSIS packages from C# without SQL Server 2005 Developer or Enterprise edition installed (“go Microsoft!”).
Another important caveat… you CAN have your unit test project in the same solution as your SSIS project. Due to over-excessive design time validation of SSIS packages, you can’t effectively execute the SSIS packages from your unit test code if you have the SSIS project loaded at the same time. I’ve found that the only way I can safely run my unit tests is to “Unload Project” on the SSIS project before attempting to execute the unit test host app. Even then, Visual Studio occassionally holds locks on files that force me to close and re-open Visual Studio in order to release them.
Anyway, I chose to use a console application as the host app. There’s some info out there on the ‘net about how to configure a .config file borrowing from dtexec.exe.config, the SSIS command line utility, but I didn’t see anything special in there that I had to include.
The only reference you need to add to your project is a ref to Microsoft.SqlServer.ManagedDTS. The core namespace you’ll need is
using Microsoft.SqlServer.Dts.Runtime;
In my first case, most of my unit testing is variations on a single input file. The package validates the input and produces three outputs: a table that contains source records which have passed validation, a flat output file that contains source records that failed validation, and a target table that contains transformed results.
What I ended up doing was creating a very small framework that allowed me to declare a test and some metadata about it. The metadata associates a group of resources that include a test input, and the three baseline outputs by a common URN. Once I have my input and baselines established, I can circumvent downloading the “real” source file, inject my test source into the process, and compare the results with my baselines.
Here’s an example Unit test of a Validation executable within my SSIS package:
[TestInfo(Name = "Unit: Validate Source, duplicated line in source", TestURN = "Dupes")]
public void ValidationUnitDupeLineTest()
{
using (Package thePackage = _dtsApp.LoadPackage(packageFilePath, this))
{
thePackage.DelayValidation = true;
DisableAllExecutables(thePackage);
EnableValidationExecutable(thePackage);
InjectBaselineSource(GetBaselineResource("Stage_1_Source_" + TestURN), thePackage.Variables["SourceFilePath"]);
thePackage.Execute(null, null, this, null, null);
string errorFilePath = thePackage.Variables["ErrorLogFilePath"].Value as string;
//throw new AbortTestingException();
AssertPackageExecutionResult(thePackage, DTSExecResult.Failure);
AssertBaselineAdjustSource(TestURN);
AssertBaselineFile(GetBaselineResourceString("Baseline_Stage1_" + TestURN), errorFilePath);
}
}
Here’s the code that does some of the SSIS Package manipulation referenced above:
#region Utilities
protected virtual void DisableAllExecutables(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
(aContainer.Executables["Download Source From SharePoint"] as TaskHost).Disable = true;
(aContainer.Executables["Prep Target Tables"] as TaskHost).Disable = true;
(aContainer.Executables["Validate Source Data"] as TaskHost).Disable = true;
(aContainer.Executables["Process Source Data"] as TaskHost).Disable = true;
(aContainer.Executables["Source Validation Failure Sequence"] as Sequence).Disable = true;
(aContainer.Executables["Execute Report Subscription"] as TaskHost).Disable = true;
(thePackage.Executables["Package Success Sequence"] as Sequence).Disable = true;
(thePackage.Executables["Package Failure Sequence"] as Sequence).Disable = true;
}
protected virtual void DisableDownloadExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost dLScriptTask = aContainer.Executables["Download Source From SharePoint"] as TaskHost;
dLScriptTask.Disable = true;
}
protected virtual void EnableValidationExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost validationFlow = aContainer.Executables["Validate Source Data"] as TaskHost;
validationFlow.Disable = false;
}
protected virtual void EnableValidationExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost validationFlow = aContainer.Executables["Validate Source Data"] as TaskHost;
validationFlow.Disable = false;
}
Another really handy thing to be aware of…
I highly recommend you implement this interface and pass it into your packages. Of course, in each event handler in the interface, implement code to send reasonable information to an output stream. Notice the call to thePackage.Execute, way up in the first code snippet… the class that contains that method implements that interface, so I can manipulate (when necessary) how to handle certain events.
Interestingly, I haven’t needed to do anything fancy with that so far, but I can imagine that functionality being very important in future unit tests that I write.
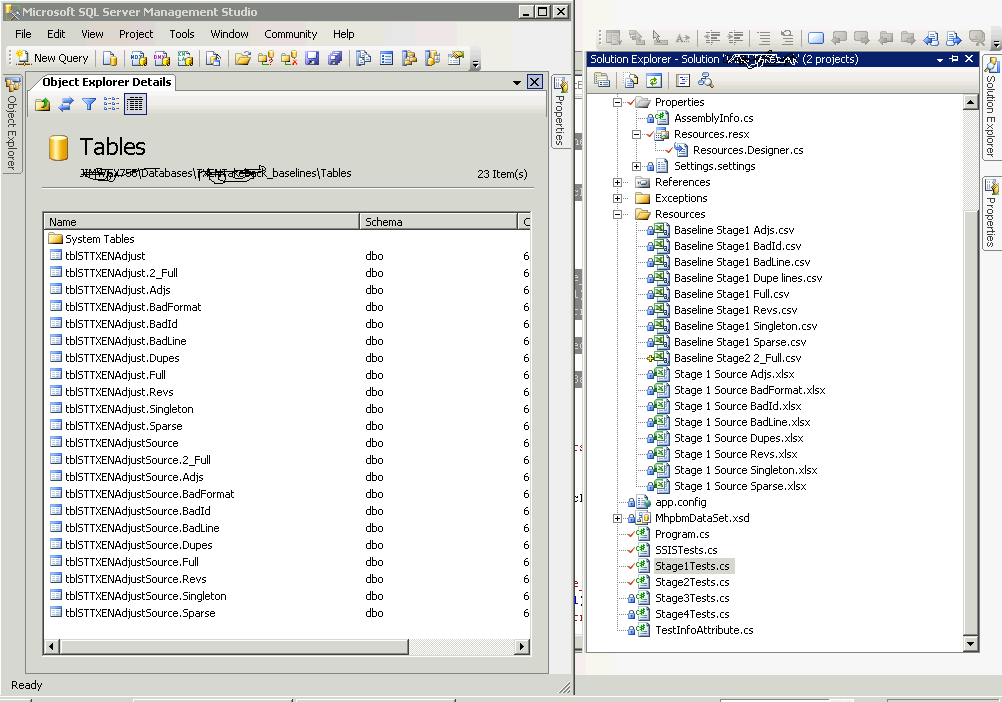 Here’s a visual on all the resources… the image shows SSMS over VS, with both database tables and project resources with common URNs to relate them.
Here’s a visual on all the resources… the image shows SSMS over VS, with both database tables and project resources with common URNs to relate them.
I won’t get into the details of the framework functionality, but I found it useful to be able to do things like set a flag to rebuild baseline resources from current outputs, and such.
I modeled some of my framework (very loosely) functionality on the Visual Studio Team System Edition for Testers, which we used on the TWM ISIS project.
Another interesting lesson learned: I can see that the folks who built SSIS were not avid unit testers themselves. SSIS Executables have a “Validate()” method. I encountered lots of problems when I tried to use it. Hangs, intermittent errors, all that stuff that testing should have ironed out.