I’ve been evangelizing code generation since the work I did at Providus / FRS Global…
One of my arguements on the topic got published by Edgewater…
I love the picture on it… 🙂
Granite State Users Groups, LLC
#NHCommunityEnabled
I’ve been evangelizing code generation since the work I did at Providus / FRS Global…
One of my arguements on the topic got published by Edgewater…
I love the picture on it… 🙂
I’ve been having fun (ya, really… fun!) with MS VPC 2007 SP1 lately.
I’ve put some VM’s on a portable USB disk. USB2 isn’t the best connection, but it’s workable. It does a few things… adds a spindle to the system config, offloading that overhead from the main disk.
An external disk also means the VM is “portable”. I can launch the VM on my laptop or any other host system (like my home system) without any significant difficulty. Even better, by having the VPC config files on the host, rather than on the external disk, you can tune VM settings (like memory and network connectivity) for optimal conditions on the host system.
One other nice time-saver is differencing disks. You can create a “base” virtual hard disk, and create VHD’s that are deltas of the base… by doing this, you can create a primary configuration, and then create several machines that inherit that basic config. It came in very handy for a recent product evaluation… I just created a base VM roughly according to what the client expects to host the system on, and then created VMs based on that for each product I wanted to evaluate.
Another nice feature is virtual assist hardware. At first, I didn’t know my ThinkPad had it, but it turns out to be a BIOS setting. Flip that on, do a cold boot, and VM performance is visibly better. I knew of some of the other features from past experience with MS VPC 2005, but the hardware acceleration is new to me. (Ironically, my newer home desktop, a 64-bit monster with huge RAM doesn’t support the hardware assist… performance isn’t a problem, there, tho. )
One more trick: enable the Undo disk option… It put another layer of protection on your VM, allowing you snap a line on your VM at a point in time that you can back-out to. The cool part about this is that the Undo disk is created as a temporary file on the host system, (typically on the primary system drive). This distributes load across the spindles even more, which further improves run-time performance. The downside: when it comes time to commit the undo, it can take a while.
I still love the idea, going forward, of putting client dev environments on a config like this… Not only does it create a nice level of separation between client system configurations, but when you get your hands on better hardware, migration is not an issue.
In trying to drive a process from a SharePoint list, I ran across a problem…
I couldn’t create a web reference in my C# project due to some really weird problem… In the “Add web reference” wizard, I entered my URL, and was surprised by a pop-up titled “Discovery Credential”, asking me for credentials for the site.
Since I was on the local domain and had “owner” permissions to the site, I thought I would just waltz in and get the WSDL.
Ok, so it wants creds… I gave it my own.
Negative…!?!?
After a few attempts and access denied errors, I hit Cancel, and was rewarded by, of all things, the WSDL display… but I still couldn’t add the reference.
After quite a bit of wrestling, it turns out there was an authentication provider configuration problem. The site was configured to use Kerberos authentication, but the active directory configuration was not set up correctly. (I believe it needed someone to use SetSPN to update the Service Principal Name (SPN) for the service.)
One way to resolve the problem was to set the authentication provider to NTLM, but in my case, I didn’t have, (and wasn’t likely to get) that configuration changed in the site (a SharePoint Web Application) I really needed access to.
In order to make it work, I had to initially create my reference to a similar, accessible site.
(e.g. http://host/sites/myaccessiblesite/_vti_bin/lists.asmx )
Then, I had to initialize the service as such, in code:
private void InitWebService()
{
System.Net.AuthenticationManager.Unregister("Basic");
System.Net.AuthenticationManager.Unregister("Kerberos");
//System.Net.AuthenticationManager.Unregister("Ntlm");
System.Net.AuthenticationManager.Unregister("Negotiate");
System.Net.AuthenticationManager.Unregister("Digest");
SmokeTestSite.Lists workingLists = new SmokeTest.SmokeTestSite.Lists();
workingLists.Url = "http://host/sites/mybrokensite/_vti_bin/lists.asmx";
workingLists.UseDefaultCredentials = true;
workingLists.Proxy = null;
lists = workingLists;
}
What this accomplishes is it unregisters all authentication managers in your application domain. (This can only be done once in the same app domain. Attempts to unregister the same manager more than once while the program’s running will throw an exception.)
So by having all the other authentication managers disabled in the client, the server would negotiate and agree on Ntlm authentication, which succeeds.
The past couple weeks, I’ve been between projects, which has gotten me involved in a number of “odd jobs”. An interesting pattern that I’m seeing in them is querying and joining, and updating data from very traditionally “unlikely” sources… especially code.
SQL databases are very involved, but I find myself querying system views of the schema itself, rather than its contents. In fact, I’m doing so much of this, that I’m finding myself building skeleton databases… no data, just schema, stored procs, and supporting structures.
I’m also pulling and updating metadata from the likes of SharePoint sites, SSRS RDL files, SSIS packages… and most recently, CLR objects that were serialized and persisted to a file. Rather than outputting in the form of reports, in some cases, I’m outputting in the form of more source code.
I’ve already blogged a bit about pulling SharePoint lists into ADO.NET DataSet’s. I’ll post about some of the other fun stuff I’ve been hacking at soon.
I think the interesting part is how relatively easy it’s becoming to write code to “ETL” source code.
[Feb 18, 2009: I’ve posted an update to show the newer technique suggested below by Kirk Evans, also compensating for some column naming issues.]
The other day, I needed to write some code that processed data from a SharePoint list. The list was hosted on a remote MOSS 2007 server.
Given more time, I’d have gone digging for an ADO.NET adapter, but I found some code that helped. Unfortunately, the code I found didn’t quite seem to work for my needs. Out of the box, the code missed several columns for no apparent reason.
Here’s my tweak to the solution:
(The ListWebService points to a web service like http://SiteHost/SiteParent/Site/_vti_bin/lists.asmx?WSDL )
private data.DataTable GetDataTableFromWSS(string listName)
{
ListWebService.Lists lists = new ListWebService.Lists();
lists.UseDefaultCredentials = true;
lists.Proxy = null;
//you have to pass the List Name here
XmlNode ListCollectionNode = lists.GetListCollection();
XmlElement List = (XmlElement)ListCollectionNode.SelectSingleNode(String.Format(“wss:List[@Title='{0}’]”, listName), NameSpaceMgr);
if (List == null)
{
throw new ArgumentException(String.Format(“The list ‘{0}’ could not be found in the site ‘{1}'”, listName, lists.Url));
}
string TechListName = List.GetAttribute(“Name”);
data.DataTable result = new data.DataTable(“list”);
XmlNode ListInfoNode = lists.GetList(TechListName);
System.Text.StringBuilder fieldRefs = new System.Text.StringBuilder();
System.Collections.Hashtable DisplayNames = new System.Collections.Hashtable();
foreach (XmlElement Field in ListInfoNode.SelectNodes(“wss:Fields/wss:Field”, NameSpaceMgr))
{
string FieldName = Field.GetAttribute(“Name”);
string FieldDisplayName = Field.GetAttribute(“DisplayName”);
if (result.Columns.Contains(FieldDisplayName))
{
FieldDisplayName = FieldDisplayName + ” (“ + FieldName + “)”;
}
result.Columns.Add(FieldDisplayName, TypeFromField(Field));
fieldRefs.AppendFormat(“”, FieldName);
DisplayNames.Add(FieldDisplayName, FieldName);
}
result.Columns.Add(“XmlElement”, typeof(XmlElement));
XmlElement fields = ListInfoNode.OwnerDocument.CreateElement(“ViewFields”);
fields.InnerXml = fieldRefs.ToString();
XmlNode ItemsNode = lists.GetListItems(TechListName, null, null, fields, “10000”, null, null);
// Lookup fields always start with the numeric ID, then ;# and then the string representation.
// We are normally only interested in the name, so we strip the ID.
System.Text.RegularExpressions.Regex CheckLookup = new System.Text.RegularExpressions.Regex(“^\\d+;#”);
foreach (XmlElement Item in ItemsNode.SelectNodes(“rs:data/z:row”, NameSpaceMgr))
{
data.DataRow newRow = result.NewRow();
foreach (data.DataColumn col in result.Columns)
{
if (Item.HasAttribute(“ows_” + (string)DisplayNames[col.ColumnName]))
{
string val = Item.GetAttribute(“ows_” + (string)DisplayNames[col.ColumnName]);
if (CheckLookup.IsMatch((string)val))
{
string valString = val as String;
val = valString.Substring(valString.IndexOf(“#”) + 1);
}
// Assigning a string to a field that expects numbers or
// datetime values will implicitly convert them
newRow[col] = val;
}
}
newRow[“XmlElement”] = Item;
result.Rows.Add(newRow);
}
return result;
}
// The following Function is used to Get Namespaces
private static XmlNamespaceManager _nsmgr;
private static XmlNamespaceManager NameSpaceMgr
{
get
{
if (_nsmgr == null)
{
_nsmgr = new XmlNamespaceManager(new NameTable());
_nsmgr.AddNamespace(“wss”, “http://schemas.microsoft.com/sharepoint/soap/”);
_nsmgr.AddNamespace(“s”, “uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882”);
_nsmgr.AddNamespace(“dt”, “uuid:C2F41010-65B3-11d1-A29F-00AA00C14882”);
_nsmgr.AddNamespace(“rs”, “urn:schemas-microsoft-com:rowset”);
_nsmgr.AddNamespace(“z”, “#RowsetSchema”);
}
return _nsmgr;
}
}
private Type TypeFromField(XmlElement field)
{
switch (field.GetAttribute(“Type”))
{
case “DateTime”:
return typeof(DateTime);
case “Integer”:
return typeof(int);
case “Number”:
return typeof(float);
default:
return typeof(string);
}
}
In doing some research for a client on workflow in SharePoint, I came across this interesting article about the differences between BizTalk 2006 and the .NET Workflow Foundation (WF).
The article itself was worth the read for its main point, but I was also interested in Microsoft’s Application Platform Infrastructure Optimization (“APIO”) model.
The “dynamic” level of the APIO model describes the kind of system that I believe the .NET platform has been aiming at since 3.0.
I’ve been eyeing the tools… between MS’s initiatives, my co-workers’ project abstracts, and the types of work that’s coming down the pike in consulting. From the timing of MS’s releases, and the feature sets thereof, I should have known that the webinars they’ve released on the topic have been around for just over a year.
This also plays into Microsoft Oslo. I have suspected that Windows Workflow Foundation, or some derivative thereof, is at the heart of the modeling paradigm that Oslo is based on.
All this stuff feeds into a hypothesis I’ve mentioned before that I call “metaware”, a metadata layer on top of software. I think it’s a different shade of good old CASE… because, as we all know… “CASE is dead… Long live CASE!”
One of the things I’ve been intrigued by for a while now is the fact that code compiled for the .NET Compact Framework (all versions) executes very nicely on the full .NET Framework.
For example, my personal hobby project, “Jimmy Sudoku”, is written in C# for the .NET Compact Framework 2.0. There are actually two install kits. The first is a .CAB file for Windows Mobile devices. The second is an .MSI for Windows 9x, XP, and Vista. The desktop install kit even serves two purposes. First, it installs the program on the desktop. Second, it leverages ActiveSync to push the .CAB up to the Windows Mobile device.
It’s a .NET Compact Framework app especially for Windows Mobile devices, but many ‘Jimmy’ fans don’t have a Windows Mobile device to run it on.
The coolest part is the ease in which all of the components inter-operate. The .EXE and .DLL’s that are delivered to the mobile device are the very same as the ones that are delivered to the desktop. Like Silverlight to WPF, the Compact Framework is a compatible subset of the full framework, so interoperability is a given.
Even better, you can reference CF assemblies in Full framework assemblies. One immediate offshoot of this in my hobby project… the web service I built to service “Game of the Day” requests actually references the CF assembly that implements the game state model and game generator code. The assembly that generates games on Windows Mobile PDA’s & cell phones is the very same assembly that generates games in the ASP.NET web service.
Admittedly, there are some bothersome differences between the CF and the Full .NET Framework. The CF does not support WPF. The CF has no facilities for printing. Also, while the CF does supports some of the common Windows Forms dialogs, it does not support File Save and File Open dialogs on Windows Mobile Standard Edition (Smart Phone / non-touchscreen) devices.
These differences can be overlooked to some extent, though, for the fact that one compiled assembly can execute on so many very different machine types. Further, with interoperability, one can extend a CF-based core code with full-framework support. For example, I’m currently playing with desktop print functionality for my hobby project.
Something that I’d really love to see, some day, is a good excuse to develop a Windows Forms app for a client that had shared components between the desktop and a mobile.
I can imagine that this model would be superb for a huge variety of applications, allowing a fully featured UI for the desktop version, and an excellent, 100% compatible, very low risk (almost “free”) portable version.
I’ve often thought this would work great for apps that interface hardware, like:
field equipment,
mobile equipment,
vehicles of all sorts,
…simply plug in your PDA (via USB or Bluetooth), and it becomes a smart management device for the equipment, using the very same code that also runs on the desktop.
SSIS Data flows can be really complex. Worse, you really can’t execute portions of a single data flow separately and get meaninful results.
Further, one of the key features of SSIS is the fact that the built-in data flow toolbox items can be equated to framework functionality. There’s not so much value in unit testing the framework.
Excuses come easy, but really, unit testing in SSIS is not impossible…
So meaningful unit testing of SSIS packages really comes down to testing of Executables in a control flow, and particularly executables with a high degree of programability. The two most significant control flow executable types are Script Task executables and Data Flow executables.
Ultimately, the solution to SSIS unit testing becomes package execution automation.
There are a certain number of things you have to do before you can start writing C# to test your scripts and data flows, though. I’ll go through my experience with it, so far.
In order to automate SSIS package execution for unit testing, you must have Visual Studio 2005 (or greater) with the language of your choice installed (I chose C#).
Interestingly, while you can develop and debug SSIS in the Business Intelligence Development System (BIDS, a subset of Visual Studio), you cannot execute SSIS packages from C# without SQL Server 2005 Developer or Enterprise edition installed (“go Microsoft!”).
Another important caveat… you CAN have your unit test project in the same solution as your SSIS project. Due to over-excessive design time validation of SSIS packages, you can’t effectively execute the SSIS packages from your unit test code if you have the SSIS project loaded at the same time. I’ve found that the only way I can safely run my unit tests is to “Unload Project” on the SSIS project before attempting to execute the unit test host app. Even then, Visual Studio occassionally holds locks on files that force me to close and re-open Visual Studio in order to release them.
Anyway, I chose to use a console application as the host app. There’s some info out there on the ‘net about how to configure a .config file borrowing from dtexec.exe.config, the SSIS command line utility, but I didn’t see anything special in there that I had to include.
The only reference you need to add to your project is a ref to Microsoft.SqlServer.ManagedDTS. The core namespace you’ll need is
using Microsoft.SqlServer.Dts.Runtime;
In my first case, most of my unit testing is variations on a single input file. The package validates the input and produces three outputs: a table that contains source records which have passed validation, a flat output file that contains source records that failed validation, and a target table that contains transformed results.
What I ended up doing was creating a very small framework that allowed me to declare a test and some metadata about it. The metadata associates a group of resources that include a test input, and the three baseline outputs by a common URN. Once I have my input and baselines established, I can circumvent downloading the “real” source file, inject my test source into the process, and compare the results with my baselines.
Here’s an example Unit test of a Validation executable within my SSIS package:
[TestInfo(Name = "Unit: Validate Source, duplicated line in source", TestURN = "Dupes")]
public void ValidationUnitDupeLineTest()
{
using (Package thePackage = _dtsApp.LoadPackage(packageFilePath, this))
{
thePackage.DelayValidation = true;
DisableAllExecutables(thePackage);
EnableValidationExecutable(thePackage);
InjectBaselineSource(GetBaselineResource("Stage_1_Source_" + TestURN), thePackage.Variables["SourceFilePath"]);
thePackage.Execute(null, null, this, null, null);
string errorFilePath = thePackage.Variables["ErrorLogFilePath"].Value as string;
//throw new AbortTestingException();
AssertPackageExecutionResult(thePackage, DTSExecResult.Failure);
AssertBaselineAdjustSource(TestURN);
AssertBaselineFile(GetBaselineResourceString("Baseline_Stage1_" + TestURN), errorFilePath);
}
}
Here’s the code that does some of the SSIS Package manipulation referenced above:
#region Utilities
protected virtual void DisableAllExecutables(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
(aContainer.Executables["Download Source From SharePoint"] as TaskHost).Disable = true;
(aContainer.Executables["Prep Target Tables"] as TaskHost).Disable = true;
(aContainer.Executables["Validate Source Data"] as TaskHost).Disable = true;
(aContainer.Executables["Process Source Data"] as TaskHost).Disable = true;
(aContainer.Executables["Source Validation Failure Sequence"] as Sequence).Disable = true;
(aContainer.Executables["Execute Report Subscription"] as TaskHost).Disable = true;
(thePackage.Executables["Package Success Sequence"] as Sequence).Disable = true;
(thePackage.Executables["Package Failure Sequence"] as Sequence).Disable = true;
}
protected virtual void DisableDownloadExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost dLScriptTask = aContainer.Executables["Download Source From SharePoint"] as TaskHost;
dLScriptTask.Disable = true;
}
protected virtual void EnableValidationExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost validationFlow = aContainer.Executables["Validate Source Data"] as TaskHost;
validationFlow.Disable = false;
}
protected virtual void EnableValidationExecutable(Package thePackage)
{
Sequence aContainer = thePackage.Executables["Adjustments, Stage 1"] as Sequence;
TaskHost validationFlow = aContainer.Executables["Validate Source Data"] as TaskHost;
validationFlow.Disable = false;
}
Another really handy thing to be aware of…
I highly recommend you implement this interface and pass it into your packages. Of course, in each event handler in the interface, implement code to send reasonable information to an output stream. Notice the call to thePackage.Execute, way up in the first code snippet… the class that contains that method implements that interface, so I can manipulate (when necessary) how to handle certain events.
Interestingly, I haven’t needed to do anything fancy with that so far, but I can imagine that functionality being very important in future unit tests that I write.
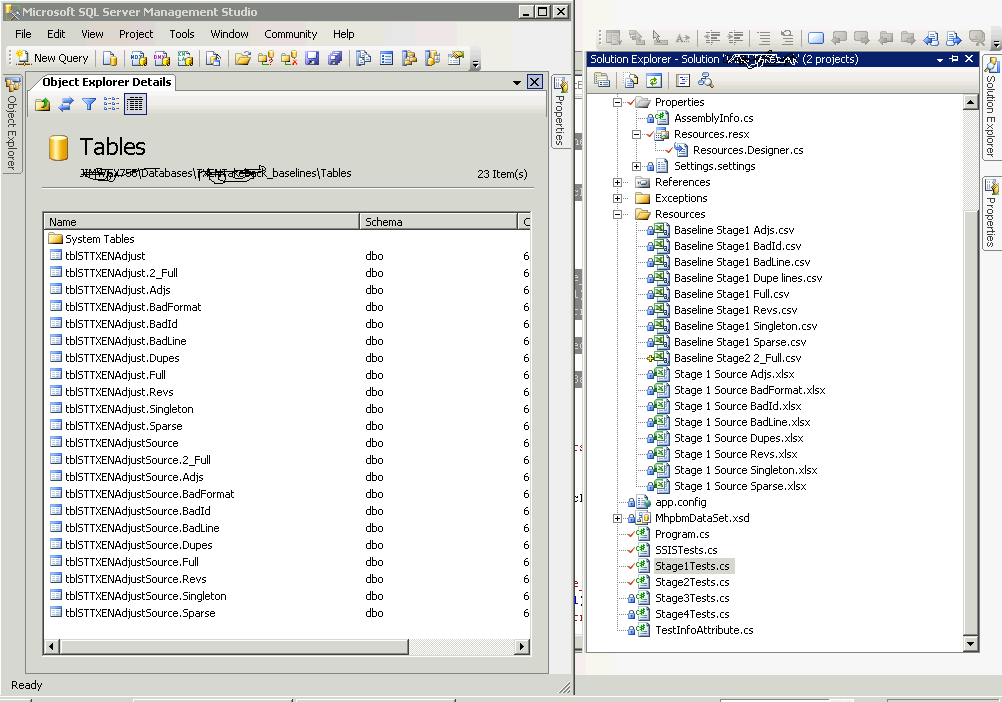 Here’s a visual on all the resources… the image shows SSMS over VS, with both database tables and project resources with common URNs to relate them.
Here’s a visual on all the resources… the image shows SSMS over VS, with both database tables and project resources with common URNs to relate them.
I won’t get into the details of the framework functionality, but I found it useful to be able to do things like set a flag to rebuild baseline resources from current outputs, and such.
I modeled some of my framework (very loosely) functionality on the Visual Studio Team System Edition for Testers, which we used on the TWM ISIS project.
Another interesting lesson learned: I can see that the folks who built SSIS were not avid unit testers themselves. SSIS Executables have a “Validate()” method. I encountered lots of problems when I tried to use it. Hangs, intermittent errors, all that stuff that testing should have ironed out.
Multi-point touch screen systems are starting to take shape out of the ether, and it really feels like it’s going to usher in a new era of computing. We’ve talked about a few of them here in the Tech Mill. It’s “Minority Report” without the goofy VR glove.
Microsoft’s offering in this arena is Surface (formerly “Milan”).( http://www.microsoft.com/surface )
From available marketing materials, Surface is much like the other offerings that are under development, with a few interesting differences. Rather than being an interactive “wall”, it’s a “table”. In addition to interacting to a broad range of touch-based gestures, Surface also interacts with objects. Some of it’s marketed use-cases involve direct interaction with smartphone, media, and storage devices.
This week, I’m on a training assignment in New Jersey, but within a bus ride to one of very few instances of Surface “in the wild”.
I made it a secondary objective to hit one of the AT&T stores in mid-town Manhattan.
I had a lot of high expectations for it, so actually getting to play a bit with it struck me as a touch anti-climactic. The UI was great, but it was clear they cut costs on hardware a bit: responsiveness wasn’t quite as smooth as the web demos. It did impress me with the physics modeling of the touch gestures… dragging “cards” around the table with one finger mimicked the behavior of a physical card, pivoting around the un-centered touch point as a real one would.
 I was also a bit concerned that the security devices attached to the cell phones they had around the table were some sort of transponder to hide “vapor-ware” special effects. My own phone (an HTC Mogul by Sprint) was ignored when I placed it on the table.
I was also a bit concerned that the security devices attached to the cell phones they had around the table were some sort of transponder to hide “vapor-ware” special effects. My own phone (an HTC Mogul by Sprint) was ignored when I placed it on the table.
All in all, I was happy to finally get to play with it. Between technology advances and price drops, this UI paradigm will start to make it into the power business user’s desk.
I mean, can you imagine, for example, cube analysis…. data mining… report drilling… and then with a few gestures, you transform the results into charts and graphs… then throw those into a folder on your mobile storage / pda device…
I’m still loving the idea of interactivity between physical and virtual (and/or remote) logical constructs…
Imagine bringing up the file server and your laptop on a “Surface” UI, and litterally loading it with data and installing software with the wave of your hand….
or…
Having a portable “PDA” device with “big” storage… in fact, big enough to contain a virtual PC image… In stand-alone mode, the PDA runs the VPC in a “smart display” UI. When you set it on a Surface, the whole VPC sinks into it. You get access to all the Surface functional resources including horsepower, connectivity, additional storage, and the multi-touch UI while the PDA is in contact. When you’re done, the VPC transfers back to the PDA, and you can take it to the next Surface UI in your room at the hotel, or the board room (which has one giant “Surface” as the board room table.)
 The preview is over at AT&T today. According to Wikipedia, Microsoft expects they can get these down to consumer price ranges by 2010 (two years!).
The preview is over at AT&T today. According to Wikipedia, Microsoft expects they can get these down to consumer price ranges by 2010 (two years!).
I remember reading an article, a few years back…
The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software
Its tagline: “The biggest sea change in software development since the OO revolution is knocking at the door, and its name is Concurrency.”
Mr. Sutter’s article suggests that because CPUs are now forced to improve performance through multi-core architectures, applications will need to typically employ multi-threading to gain performance improvements on newer hardware. He made a great argument. I remember getting excited enough to bring up the idea to my team at the time.
There are a number of reasons why the tag line and most of its supporting arguments appeared to fail, and in retrospect, could have been predicted.
So in today’s age of multi-core processing, where application performance gains necessarily come from improved hardware throughput, why does it still feel like we’re getting a free lunch?
To some extent, Herb was right. I mean, really, a lot of applications, by themselves, are not getting as much out of their host hardware as they could.
Before and since this article, I’ve written multi-threaded application code for several purposes. Each time, the threading was in UI code. The most common reason for it: to monitor extra-process activities without blocking the UI message pump. Yes, that’s right… In my experience, the most common reason for multi-threading is, essentially, to allow the UI message pump to keep pumping while waiting for… something else.
But many applications really have experienced significant performance improvements in multi-processor / multi-core systems, and no additional application code was written, changed, or even re-compiled to make that happen.
How?
Today’s computers are typically doing more, all the time. The OS itself has a lot of overhead, especially Windows-based systems. New Vista systems rely heavily on multi-processing to get performance for the glitzy new GUI features.
The key is multi-processing, though, rather than multi-threading. Given that CPU time is a resource that must be shared, having more CPUs means less scheduling collision, less single-CPU context switching.
Many architectures are already inherent multi-processors. A client-server or n-tier system is generally already running on a minimum of two separate processes. In a typical web architecture, with an enterprise-grade DBMS, not only do you have built-in “free” multi-processing, but you also have at least some built-in, “free” multi-threading.
Something else that developers don’t seem to have noticed much is that some frameworks are inherently multi-threaded. For example the Microsoft Windows Presentation Foundation, a general GUI framework, does a lot of its rendering on separate threads. By simply building a GUI in WPF, your client application can start to take advantage of the additional CPUs, and the program author might not even be aware of it. Learning a framework like WPF isn’t exactly free, but typically, you’re not using that framework for the multi-threading features. Multi-threading, in that case, is a nice “cheap” benefit.
When it comes down to it, though, the biggest bottlenecks in hardware are not the processor, anyway. The front-side bus is the front-line to the CPU, and it typically can’t keep a single CPU’s working set fresh. Give it a team of CPUs to feed, and things get pretty hopeless pretty quick. (HyperTransport and QuickPath will change this, but only to the extent of pushing the bottle necks a little further away from the processors.)
So to re-cap, to date, the reason we haven’t seen a sea change in application software development is because we’re already leveraging multiple processors in many ways other than multi-threading. Further, multi-threading options have been largely abstracted away from application developers via mechanisms like application hosting, database management, and frameworks.
With things like HyperTransport (AMD’s baby) and QuickPath (Intel’s), will application developers really have to start worrying about intra-process concurrency?
I throw this one back to the Great Commandment… risk management. The best way to manage the risk of intra-process concurrency (threading) is to simply avoid it as much as possible. Continuing to use the above mentioned techniques, we let the 800-lb gorillas do the heavy lifting. We avoid struggling with race conditions and deadlocks.
When concurrent processing must be done, interestingly, the best way to branch off a thread is to treat it as if it were a separate process. Even the .NET Framework 2.0 has some nice threading mechanisms that make this easy. If there are low communications needs, consider actually forking a new process, rather than multi-threading.
In conclusion, the lunch may not always be free, but a good engineer should look for it, anyway. Concurrency is, and will always be an issue, but multi-core processors were not the event that sparked that evolution.